Collaborative work in organizations involves stakeholders with different interests & backgrounds which want to invent, design, build, analyze and manage services and products. Thereby, those stakeholders typically want to use their preferred content representations from diverse content sources and channels. Typical concerns in collaborative work are:
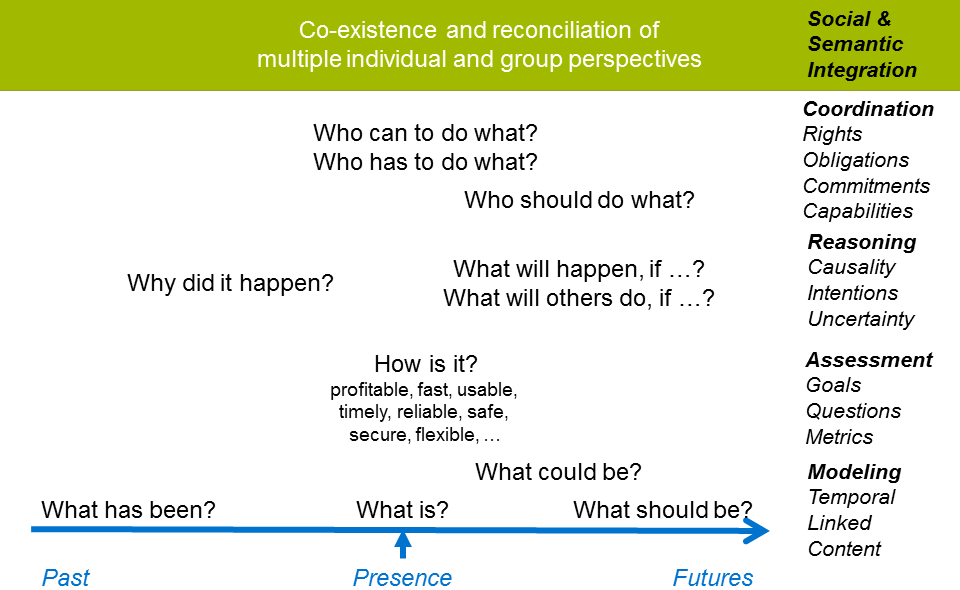
To address this plethora of concerns, organizations usually use lots of tools and systems (e.g., Wikis, CMSs, Databases) which are typically poorly integrated. Therefore, relationships between diverse entities of different sources are hard to model, analyze, and to understand, in particular when considering different content types and representations, and the relations of those entities to the respective stakeholders. As a consequence, tool-support for collaborative work requires support for knowledge-intensive processes as well as social, semantic, and content integration.
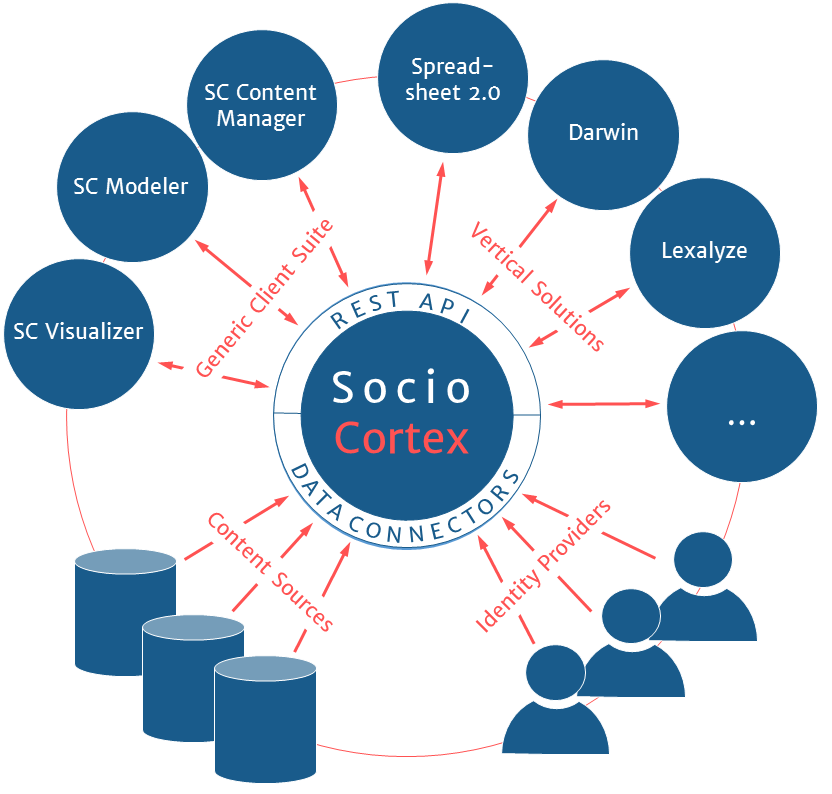
SocioCortex is the next generation of the collaborative information system which was developed at the chair for years. This system integrates proven features of SocioCortex's predecessor Tricia (e.g., the Hybrid Wiki concept) with approaches to end-user-oriented quantitative model analysis (see Spreadsheet 2.0) and the support for knowledge-intensive processes (see Darwin). By exposing its features via a standardized API, the SocioCortex plattform can serve as a foundation for the development of context-and project-specific applications.
Conceptually, the envisioned SocioCortex platform consists of seven layers: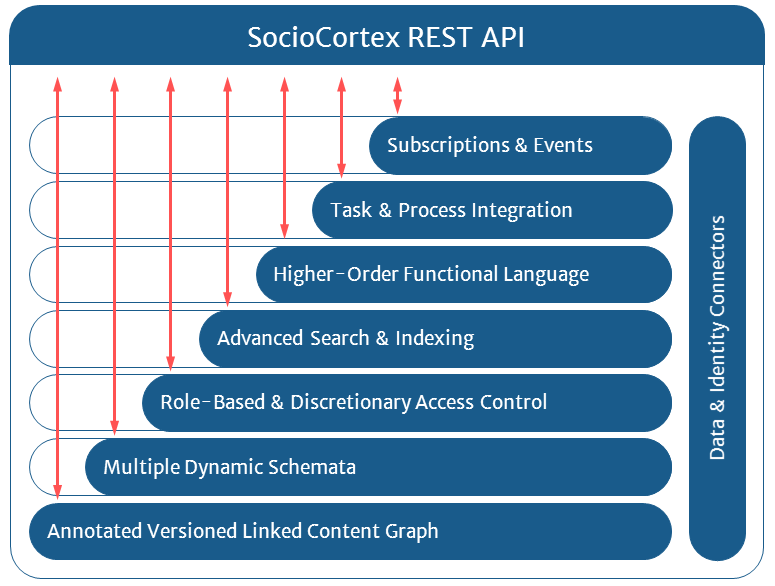
In addition to those basic layers, SocioCortex also provides facilities to integrate different kinds of data sources (e.g., relational databases) and messaging services through data and messaging connectorsrespectively. Furthermore, a bulk dump & load component enables the fast import and export of huge data sets.
Currently, the SocioCortex platform is used for the research projects Spreadsheet 2.0, Lexalyze, and Darwin.