The recent proliferation of Natural Language Processing (NLP) techniques has brought about a plethora of valuable application areas, ranging from document classification to question answering. Particularly in recent years, the rise in prominence of Language Models has enabled the rapid advancement of such use cases, and their capability has been proven to accelerate natural language understanding and generation.
Nevertheless, it has been shown that Language Models and other NLP technologies are not perfect. Concerns of factuality, fairness, sustainability, and economic viability have been raised by researchers and practitioners alike, among other pressing issues. In particular, the question of privacy has been drawn to the forefront, especially in light of the massive data processing activities required to develop modern AI systems. With such scale, concerns over the safeguarding of personal data have been raised, asking whether we can maintain such data-hungry speeds while still preserving the right to privacy.
In the technical sphere, numerous solutions have been proposed towards privacy-preserving Natural Language Processing, most often utilizing Privacy-Enhancing Technologies (PETs) at the core. Examples of PETs include encryption techniques, anonymization and sanitization methods, and most popularly, Differential Privacy (DP). This has led to the field of Differentially Private Natural Language Processing (DP NLP), which has as its main goal the optimal fusion of DP into various NLP techniques.
DP is a popular choice due to the strong privacy guarantees that it provides in data processing and sharing scenarios. Ultimately, it aims to protect an individual's privacy in the context of datasets, and it does so by providing a tunable level of indistinguishability between any two individuals in a dataset. In this sense, DP was originally created for structured datasets; however, in the textual domain, DP does not lend itself immediately to easy integration, thereby introducing challenges in both understanding and implementation.
Researchers have begun to tackle this challenge, namely to investigate how we can reason about DP in NLP, and moreover, how can an optimal balance between privacy and utility be achieved. In this, early methods address various stages of the NLP pipeline, most prominently at the data level and during model training. Apart from these differences, further challenges arise when considering the definition of the individual, as well as the choice of DP definition and the actual implementation.
At the beginning of this proposed research, the field of DP NLP was still largely an academic and theoretical concept, and understandably so, as the transfer of DP into the NLP domain required theoretical foundations. Despite this, the usability of DP NLP was very seldom considered beyond simply "making it work". Furthermore, the topic was not easy to comprehend, creating a barrier for further research as well as practical adoption. As a result, we asked one simple overarching question, which becomes the basis for this PhD work:
| How can we improve the practical usability of Differential Privacy in NLP, taking it from a purely academic (and theoretical) concept, to something that is understandable and usable? |
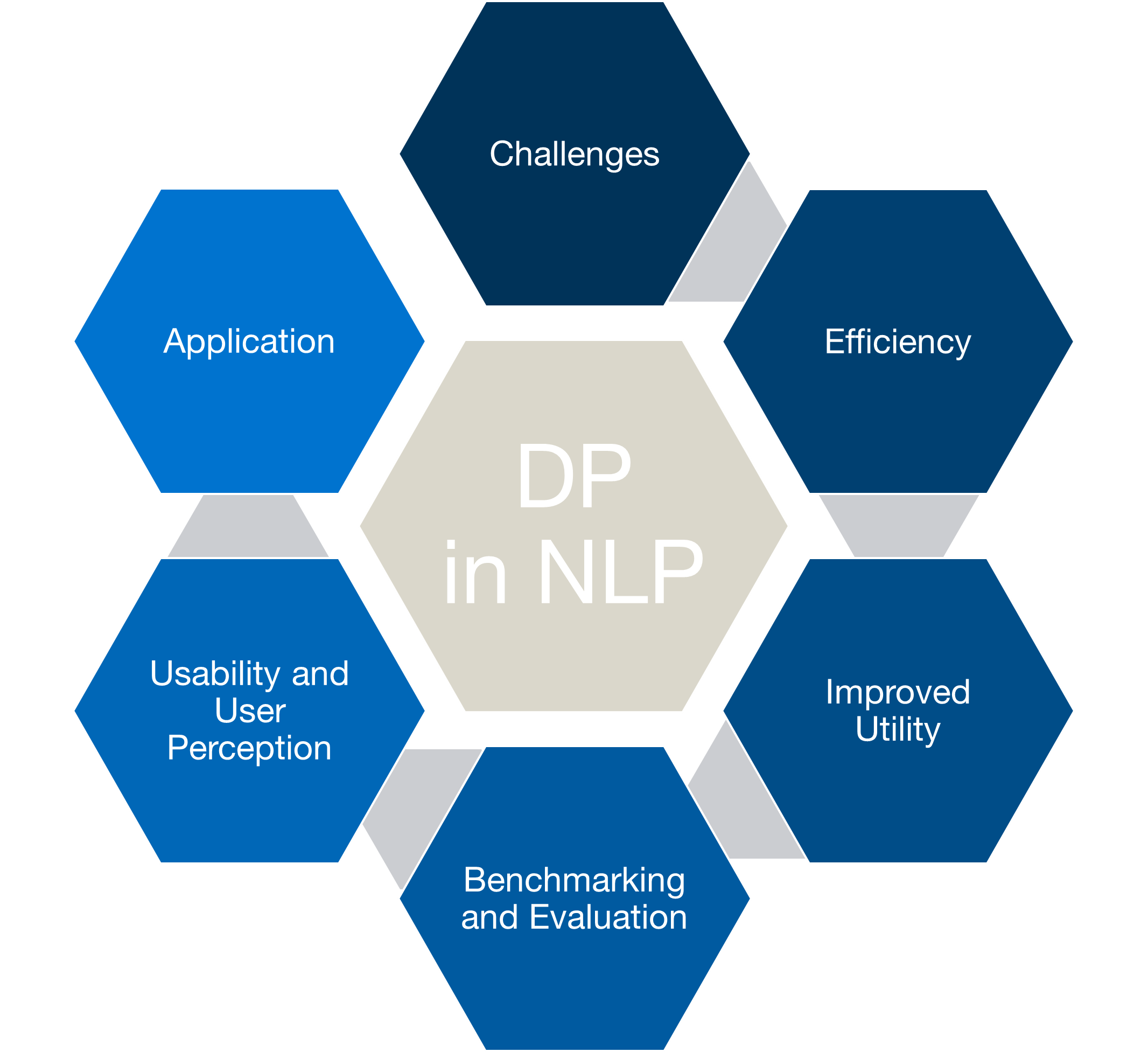
To answer this question, we break down our work into six core sub-areas: (1) Challenges, (2) Efficiency, (3) Improved Trade-off, (4) Benchmarking and Evaluation, (5) User Perception, and (6) Application. These sub-areas will guide the scope of the work, as well as present a framework towards improving the overall usability and adoptability of DP NLP.
As a result of our work, we strive to increase clarity and awareness on what it means to incorporate DP in NLP, how we can improve on current technical thinking, and what are the steps to take and the considerations to make in order to push DP NLP out of the research sphere and into practice. We see these steps as necessary progress, so that the promise of DP in the textual domain can be realized in practice and begin to make a difference.
[1] Klymenko, O.; Meisenbacher, S.; Matthes, F.: Differential Privacy in Natural Language Processing: The Story So Far. In Proceedings of the Fourth Workshop on Privacy in Natural Language Processing, pages 1–11, Seattle, United States. Association for Computational Linguistics. 2022.
[2] Meisenbacher, S.; Nandakumar, N.; Klymenko, A.; Matthes, F.: A Comparative Analysis of Word-Level Metric Differential Privacy: Benchmarking the Privacy-Utility Trade-off. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 2024.
[3] Meisenbacher S.; Chevli M.; Matthes F.: 1-Diffractor: Efficient and Utility-Preserving Text Obfuscation Leveraging Word-Level Metric Differential Privacy. In Proceedings of the 10th ACM International Workshop on Security and Privacy Analytics, pp. 23-33. 2024.
[4] Meisenbacher, S.; Matthes, F.: 2024. Just Rewrite It Again: A Post-Processing Method for Enhanced Semantic Similarity and Privacy Preservation of Differentially Private Rewritten Text. In Proceedings of the 19th International Conference on Availability, Reliability and Security (ARES '24). Association for Computing Machinery, New York, NY, USA, Article 133, 1–11.
[5] Meisenbacher, S.; Chevli, M.; Vladika, J.; Matthes, F.: 2024. DP-MLM: Differentially Private Text Rewriting Using Masked Language Models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 9314–9328, Bangkok, Thailand and virtual meeting. Association for Computational Linguistics.
[6] Meisenbacher, S.; Chevli, M.; Matthes, F.: 2024. A Collocation-based Method for Addressing Challenges in Word-level Metric Differential Privacy. In Proceedings of the Fifth Workshop on Privacy in Natural Language Processing, pages 39–51, Bangkok, Thailand. Association for Computational Linguistics.
[7] Meisenbacher, S.; Matthes, F.: 2024. Thinking Outside of the Differential Privacy Box: A Case Study in Text Privatization with Language Model Prompting. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5656–5665, Miami, Florida, USA. Association for Computational Linguistics.
[8] Meisenbacher, S.; Chevli, M.; Matthes, F.: 2025. On the Impact of Noise in Differentially Private Text Rewriting. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 514–532, Albuquerque, New Mexico. Association for Computational Linguistics.
[9] Meisenbacher, S.; Klymenko, A.; Karpp, A.; Matthes, F.: 2025. Investigating User Perspectives on Differentially Private Text Privatization. In Proceedings of the Sixth Workshop on Privacy in Natural Language Processing, pages 86–105, Albuquerque, New Mexico. Association for Computational Linguistics.
[10] Meisenbacher, S.; Lee, C.J.; Matthes, F.: 2025. Spend Your Budget Wisely: Towards an Intelligent Distribution of the Privacy Budget in Differentially Private Text Rewriting. In Proceedings of the Fifteenth ACM Conference on Data and Application Security and Privacy (CODASPY '25). Association for Computing Machinery, New York, NY, USA, 84–95.