Legal tech applications for automated legal advice such as Flightright, Bahn-Buddy, Abfindungsheld or Hartz4Widerspruch solve common simple legal problems in tightly defined applications, while being available 24/7, at a low cost. Hereby such applications focus on the accessibility for layman, as well as on the legal compliance with regard to current jurisprudence.
Generally, such systems consist of the following components:
Similarly, established products provide tax and financial advice to individuals and businesses, and to support decision-making within companies (e.g., financial accounting) and administrations (e.g., admission to enrollment). In the market, such systems are often positioned as specialized expert systems (or AI systems); a computer scientist would rather view them as classic information systems.
Hence, this research aims at supporting legal decision-making processes, which are based on legal requirements, in a dynamic fashion. For that reason, an expert systems will be developed. Such an expert system needs to provide the architecture and functionality, in order to dynamically create and infer rules which depict a decsion-making process. As a result, the system is able to capture various decision making processes.
A challenge of such systems is the acquisition of knowledge, i.e. the initial acquisition and frequent updating of the expertise of the respective domain and the correct translation by programmers into suitable data structures for knowledge representation and formal algorithms for efficient and deterministic inference. These calculate the decision or recommendation based on the case-specific facts.
This is where rule-based expert systems ("AI systems / AI platforms") such as Berkeley Bridge Software, Bryter, Checkbox, Logicnets, Neota Logic, Oracle (Policy Automation) or VisiRule systems come into play. They replace the hard-coded decision-making data structures and algorithms with a generalized reasoning engine that uses a unified language for knowledge representation (ontology language) and a uniform language for logic-based rule definition (rule language). Unlike the functional or imperative programming languages commonly used today, the order of execution of the inference steps (and possibly also the dialog steps) is not explicitly determined by the programmer, but the reasoning engine uses strategies (forward chaining, backward chaining) and heuristics, for example to logically derive legally relevant results or instructions from a given case.
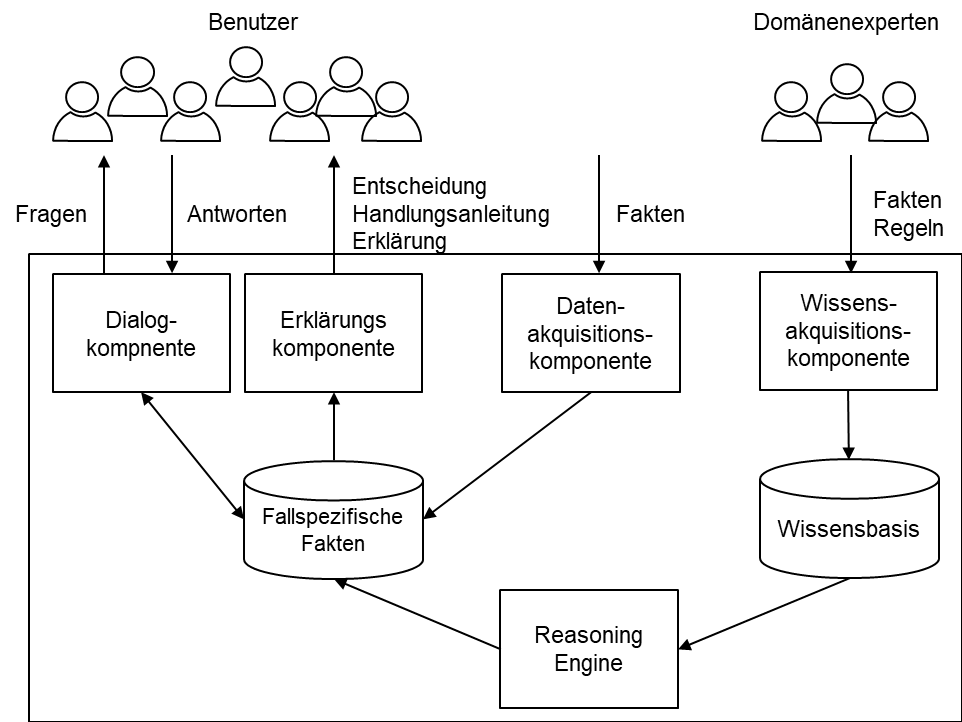
Furthermore, rule-based expert systems introduce a knowledge acquisition component that allows subject matter experts to formulate their domain knowledge in the form of facts and rules in those languages. Furthermore, the other components (dialog component, explanatory component, and data acquisition component) are generalized to also build on these generalized languages.
A reference architecture for rule-based expert systems are sketched in Figure 1, whose characteristic feature is that the knowledge base (ontology and rule set) is realized as a database. This has the following advantages: