Legal research is an essential part of many legal experts daily work [La15]. A lot of AI&Law research focuses on technical support for legal research, i.e. legal information retrieval [Op17]. Legal information retrieval has several specifics in comparison to general information retrieval, for example, different document types, large corpora, a broad range of different audiences and a specific language that uses synonymy, cf. [Op17].
Word embeddings is a technology that represents words and discrete text with continuous representations. Since the presentation of efficient methods to calculate word embeddings by Mikolov et al. [Mi13a], science experiences a significant shift towards word embeddings based representations of words and text. Word embeddings have intriguing characteristics, for example, linear regularities among word vectors, but also a tendency that synonymous words are close in the embedding space [Mi13b].
Query expansion is a frequently used approach in the legal domain to cope with the synonym used in legal language, see for example [Sc07]. In this research project, we investigate the potential of word embeddings to improve legal information retrieval with query expansion, in particular for the German legal domain.
Thesauri can be considered as lightweight ontologies that contain for example synonym groups (synsets) of terms. Thesauri are used for query expansion in legal information retrieval in a controlled fashion. Word embeddings characteristics can be used to identify synonymous words to particular words or synsets and therefore to extend existing thesauri. We investigate different word embeddings technologies such as the word2vec [Mi13a], FastText [Bo17] and GloVe [Pe14] as wells different approaches to calculate synset embeddings that can be used to identify new candidates for inclusion into synsets using cosine similarity. Parts of this research are conducted in cooperation with Datev eG on a German tax law corpus and thesaurus.
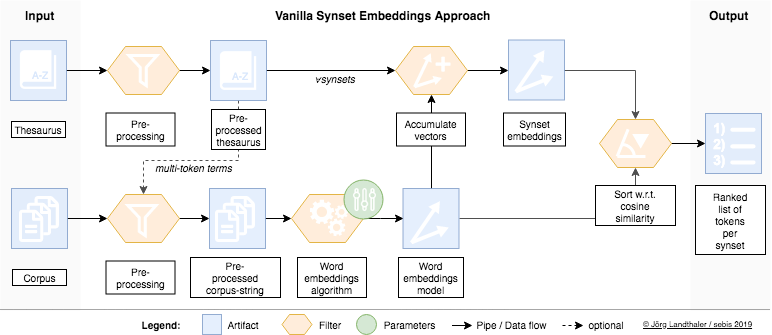
Due to the linear regularities of word embeddings, word embeddings can be accumulated to represent text. Accumulated word embeddings can be seen as an alternative document representation to traditional term frequency based document representations such as term frequency - inverse document frequency (TFIDF). A working hypothesis is that word embeddings based text representations implicitly conduct query expansion.
In parts of this research project, we focus on problems that can be described as a Semantic Text Matching problem. Semantic Text Matching is the identification of semantically and/or logically related text fragments among different documents. Citation network analysis focuses on the identification of explicit links in or among documents. Similarly, Semantic Text Matching (STM) can be seen to identify implicit links (in or) among documents. STM problems often occur in argumentation mining [Mo11] and word embeddings have been investigated as a possible solution, for example, by [Ri15] and [Na15]. Semantic Text Matching is also related to but different from textual entailment, see for example [Ad16].
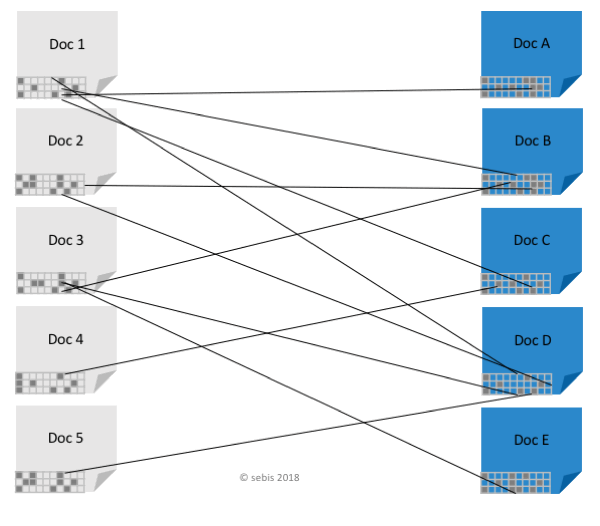
We study a particular use case in German tenancy law, where contract paragraphs are matched against legal comment chapters. To some degree, this can also be seen as a legal information retrieval task. Parts of this research are investigated with Haufe Group. A traditional search method in the legal domain is keyword search, see for example [Pe05]. In this research project, we explore Selection Search (users select text in an existing document as input to a search query) and traditional keyword search integrated into popular text processing tools in the (German) legal domain as potentially suitable human-computer interaction method that could leverage from implicit query expansion.
| 2019 | |
|---|---|
| [La19a] | Landthaler, J.; Glaser, I; Lecker, H.; Matthes, F.:User Study on Selection Search and Semantic Text Matching in German Tenancy Law, in: Weblaw, Jusletter IT 21. Februar 2019 |
| [La19a] | Landthaler, J.; Glaser, I; Lecker, H.; Matthes,F.: User Study on Selection Search and Semantic Text Matching in German Tenancy Law, IRIS: Internationales Rechtsinformatik Symposium, Salzburg, Austria, 2019 |
| 2018 | |
| [La18c] | Landthaler, J.; Glaser, I.; Matthes, F.: Explainable Semantic Text Matching, Jurix: International Conference on Legal Knowledge and Information Systems, Groningen, Netherlands (to appear) |
| [La18a] | Landthaler, J.; Scepankova, E.; Glaser, I; Lecker, H.; Matthes, F.: Semantic Text Matching of Contract Clauses and Legal Comments in Tenancy Law, IRIS: Internationales Rechtsinformatik Symposium, Salzburg, Austria, 2018 |
| 2017 | |
| [La17a] | Landthaler, J.; Waltl, B.; Huth, D.; Braun, D.; Stocker, C.; Geiger, T.; Matthes, F.: Extending Thesauri Using Word Embeddings and the Intersection Method, Proc. of 2nd Workshop on Automated Semantic Analysis of Information in Legal Texts (ASAIL’17), London, UK, June 16, 2017, CEUR-WS.org |
| 2016 | |
| [La16c] | Landthaler, J.; Waltl, B.; Holl, P.; Matthes, F.: Extending Full Text Search for Legal Document Collections using Word Embeddings, Jurix: International Conference on Legal Knowledge and Information Systems, Sofia Antopolis, France, 2016 |
[La15] Lastres, Steven A. "Rebooting legal research in a digital age." (2015).
[Op17] Van Opijnen, Marc, and Cristiana Santos. "On the concept of relevance in legal information retrieval." Artificial Intelligence and Law 25.1 (2017): 65-87.
[Mi13a] Mikolov et. al, Efficient Estimation of Word Representations in Vector Space, ICLR Workshop 2013
[Mi13b] Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
[Bo17] Bojanowski, Piotr, et al. "Enriching word vectors with subword information." Transactions of the Association for Computational Linguistics 5 (2017): 135-146.
[Pe14] Pennington, Jeffrey, Richard Socher, and Christopher Manning. "Glove: Global vectors for word representation." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[Mo11] Mochales, Raquel, and Marie-Francine Moens. "Argumentation mining." Artificial Intelligence and Law 19.1 (2011): 1-22.
[Ri15] Rinott, Ruty, et al. "Show me your evidence-an automatic method for context dependent evidence detection." Proceedings of the 2015 conference on empirical methods in natural language processing. 2015.
[Na15] Naderi, Nona, and Graeme Hirst. "Argumentation mining in parliamentary discourse." Principles and Practice of Multi-Agent Systems. Springer, Cham, 2015. 16-25.
[Ad16] Adebayo, Kolawole John, et al. "An approach to information retrieval and question answering in the legal domain." (2016).
[Pe05] Peoples, Lee F. "The death of the digest and the pitfalls of electronic research: what is the modern legal researcher to do." Law Libr. J. 97 (2005): 661.
[Sc07] Schweighofer, Erich, and Anton Geist. "Legal Query Expansion using Ontologies and Relevance Feedback." LOAIT. 2007.
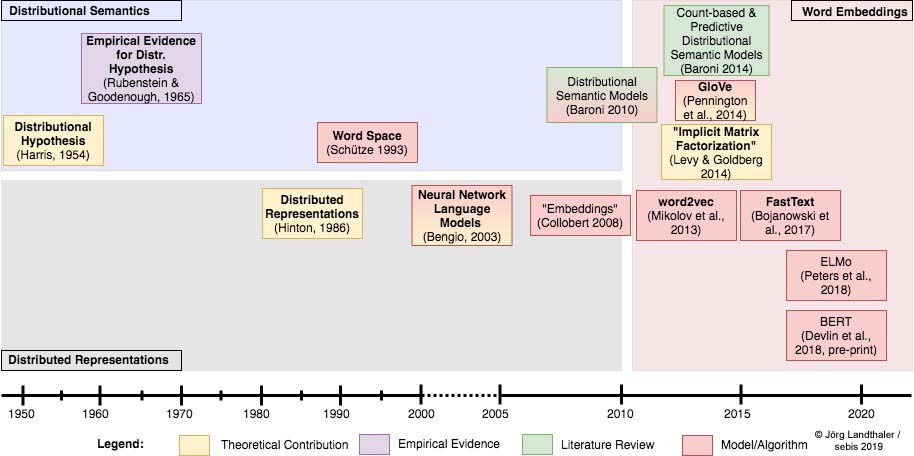
[Ha54] Harris, Zellig S. "Distributional structure." Word 10.2-3 (1954): 146-162.
[Ru64] Rubenstein, Herbert, and John B. Goodenough. "Contextual correlates of synonymy." Communications of the ACM 8.10 (1965): 627-633.
[Hi86] Hinton, Geoffrey E. "Learning distributed representations of concepts." Proceedings of the eighth annual conference of the cognitive science society. Vol. 1. 1986.
[Sc93] Schütze, Hinrich. "Word space." Advances in neural information processing systems. 1993.
[Be03] Bengio, Yoshua, et al. "A neural probabilistic language model." Journal of machine learning research 3.Feb (2003): 1137-1155.
[Co08] Collobert, Ronan, and Jason Weston. "A unified architecture for natural language processing: Deep neural networks with multitask learning." Proceedings of the 25th international conference on Machine learning. ACM, 2008.
[Ba10] Baroni, Marco, and Alessandro Lenci. "Distributional memory: A general framework for corpus-based semantics." Computational Linguistics 36.4 (2010): 673-721.
[Le14] Levy, Omer, and Yoav Goldberg. "Neural word embedding as implicit matrix factorization." Advances in neural information processing systems. 2014.
[Ba14] Baroni, Marco, Georgiana Dinu, and Germán Kruszewski. "Don't count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors." Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vol. 1. 2014.
[Pe17] Peters, Matthew, et al. "Semi-supervised sequence tagging with bidirectional language models." Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017.
[De18] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).