An estimated zettabytes of data are generated every day, with about 80% of this data being unannotated, unstructured text. An as of yet unsolved problem with this type of data is how to make it useful for AI applications. Manual annotation of the data can be very precise and incorporate domain-specific knowledge, but it is costly, inefficient, and not scalable. The so-called "80/20 rule" refers to the fact that data scientists often spend up to 80% of their time sorting, cleaning, and otherwise preparing datasets. This project aims to develop a novel hybrid framework that helps domain experts annotate text using Natural Language Processing algorithms, reducing the process to a fraction of the time. The hybrid framework will enable data scientists to create customized, domain-specific datasets for their AI applications in a short time. Especially small and medium-sized companies with only a few employees are thus supported in the development of their own AI applications.
The proposed approach is structured as a pipeline of multiple sub-tasks, all of which will leverage modern Natural Language Processing techniques to infuse domain knowledge into the dataset creation process. Starting with a corpus of unstructured (text) documents, the goal is to create meaningful datasets with defined classes (features). To accomplish this, the steps are as follows:
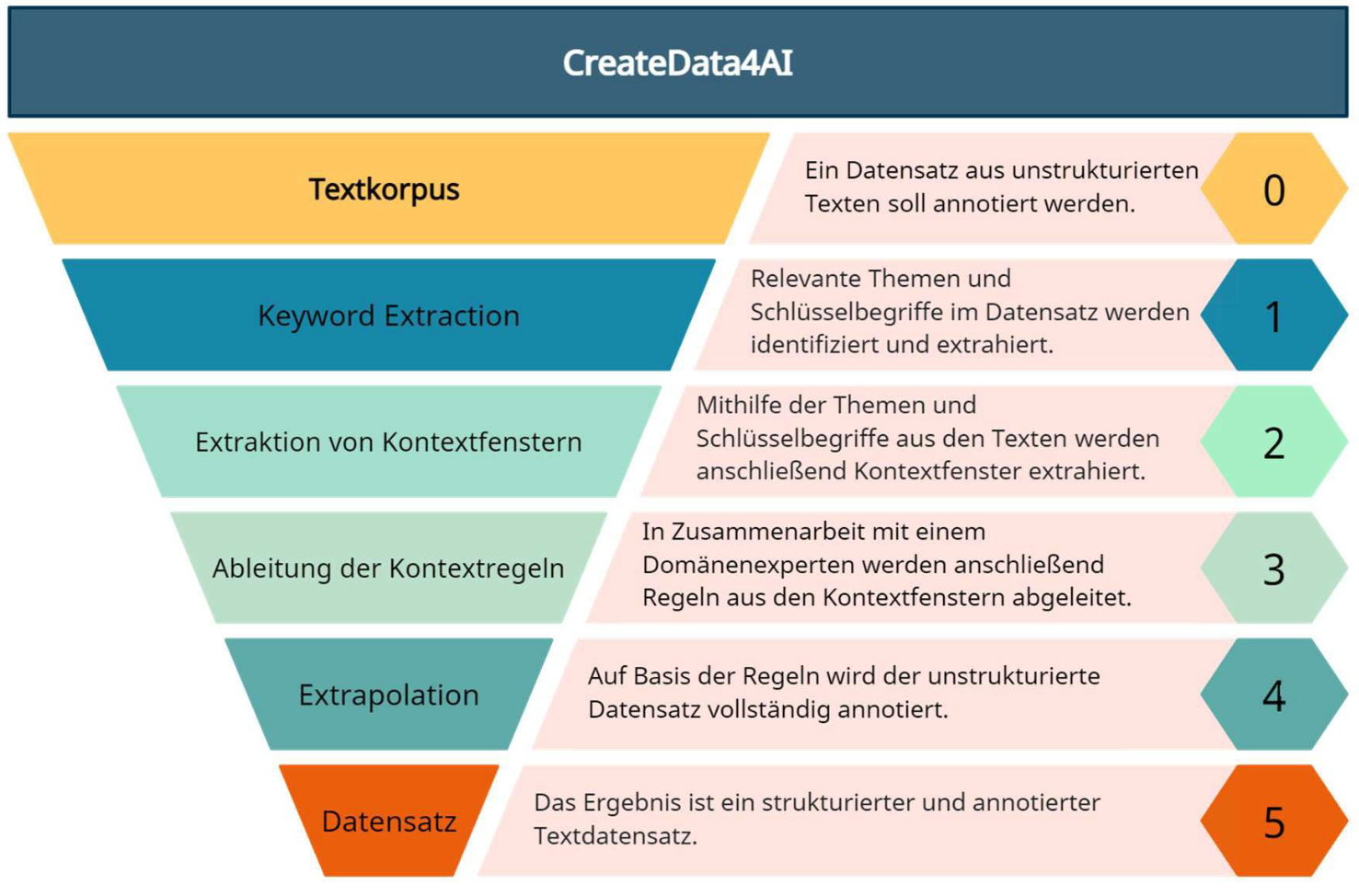
As illustrated above, the output of the prosed pipeline is a structured dataset mapping defined characteristics (classes) to individual documents.
The goal of this project is to build upon early research regarding the utilization of this new method for the creation of data with the assistance of a domain expert. The main contribution will be the stregthening of each part of the pipeline by implementing state-of-the-art techniques, as well as designing new improvements to these. In addition, the ultimate goal is to create an open-source, publicly usable website, where the fruits of the project can be explored and further utilized.
To aid in the completion of the project, the following research questions have been defined:
In what way can current state-of-the-art Natural Language Processing techniques be augmented to incorporate specific domain knowledge, with the goal of transforming unstructured text to structured datasets?
This project is supported by the Bayerisches Staatsministerium für Wirtschaft, Landesentwicklung und Energie (StMWi), and is conducted in cooperation with Fusionbase GmbH (Munich, Germany).