Nowadays, many sectors face the obstacle called digitalization. So does the legal domain as well. The rising of legal technology is highlighted by the increasing number of digitized legal documents, in particular legal contracts (Saravanan, Ravindran & Raman, 2009). After capturing these, in many cases they are only available as unstructured data and thus barely processable by computer systems. However, the semantic knowledge within such a document is highly relevant to the reader (Hammerton, 2003). Furthermore, different contracts often incorporate diverse wording, while also including a lot of superfluous information. All these facts hamper the utilization of digitized legal contracts.
This project shall provide support for this business need by supplying software components, enabling semantic analysis and structuring of legal contracts. When modeling and structuring the digitized contracts properly, a huge added value can be created (Waltl et al., 2017). For that to happen, two issues shall be solved.
Legal contracts depict complex legal concepts and structures. In order to structure these documents in a descriptive and comprehensible way, they have to be modelled properly. Hence one key task of this project is to define suitable models of contracts. Thereto, research how to define a modelling process, as well as how to depict contracts is required. A major goal thereby is to utilize SocioCortex.
Furthermore, the semantic meaning of contracts must be extracted. This meaning can be used to populate the aforementioned models. For this purpose, common Natural Language Processing (NLP) tasks like Named Entity Recognition (NER) and Named Entity Disambiguation (NED) shall be incorporated into Apache UIMA pipelines. In the scope of this project, the existing functionality of Lexia, a collaborative legal data science environment, is utilized. Hereby, the software components being developed during this project shall be integrated into Lexia.
The main research questions within this project address:
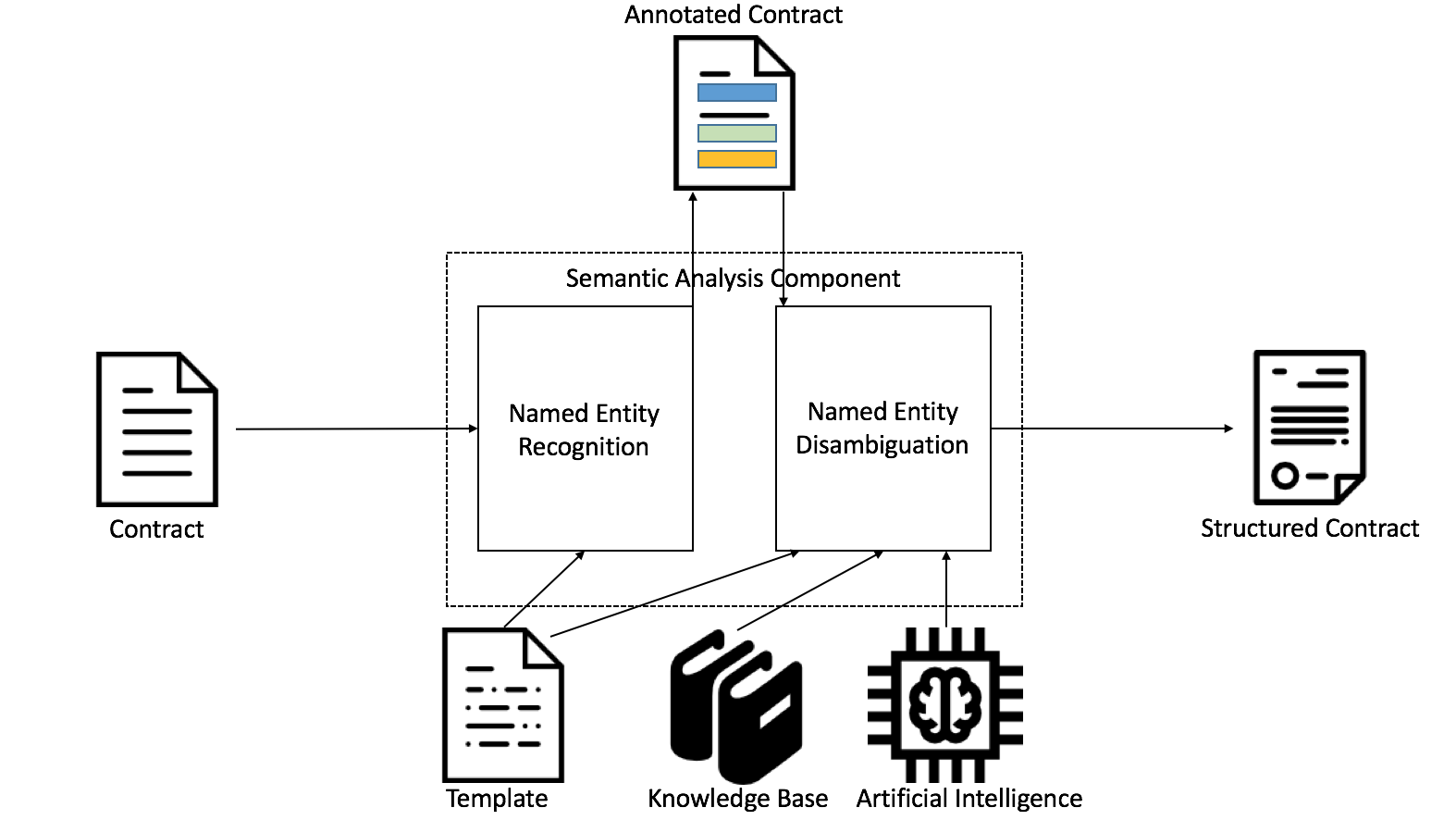
The figure above depicts the conceptual architecture of a software component to semantically analyze and structure legal contracts.
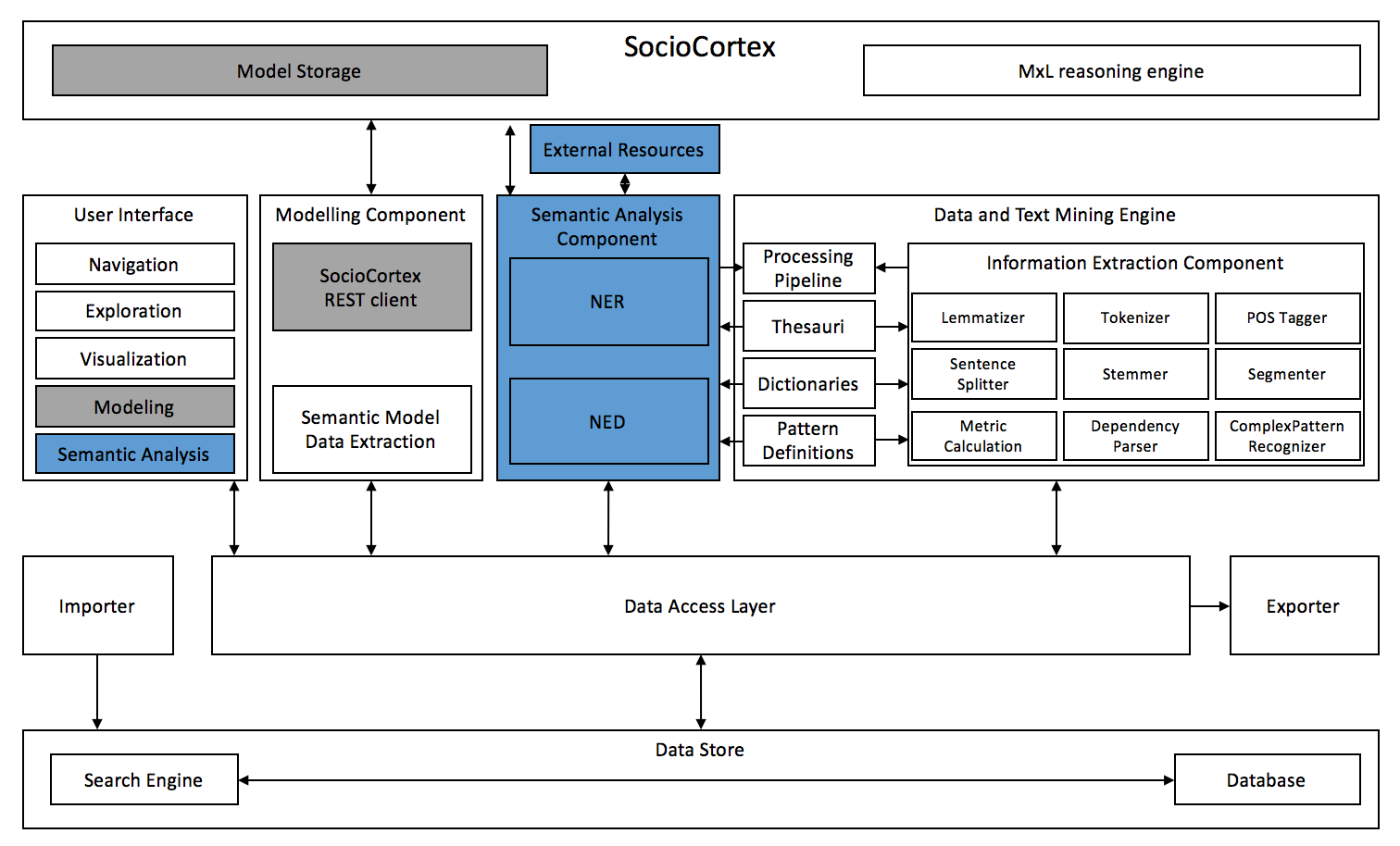
This architectural figure reveals the integration into the existing software architecture of Lexia.
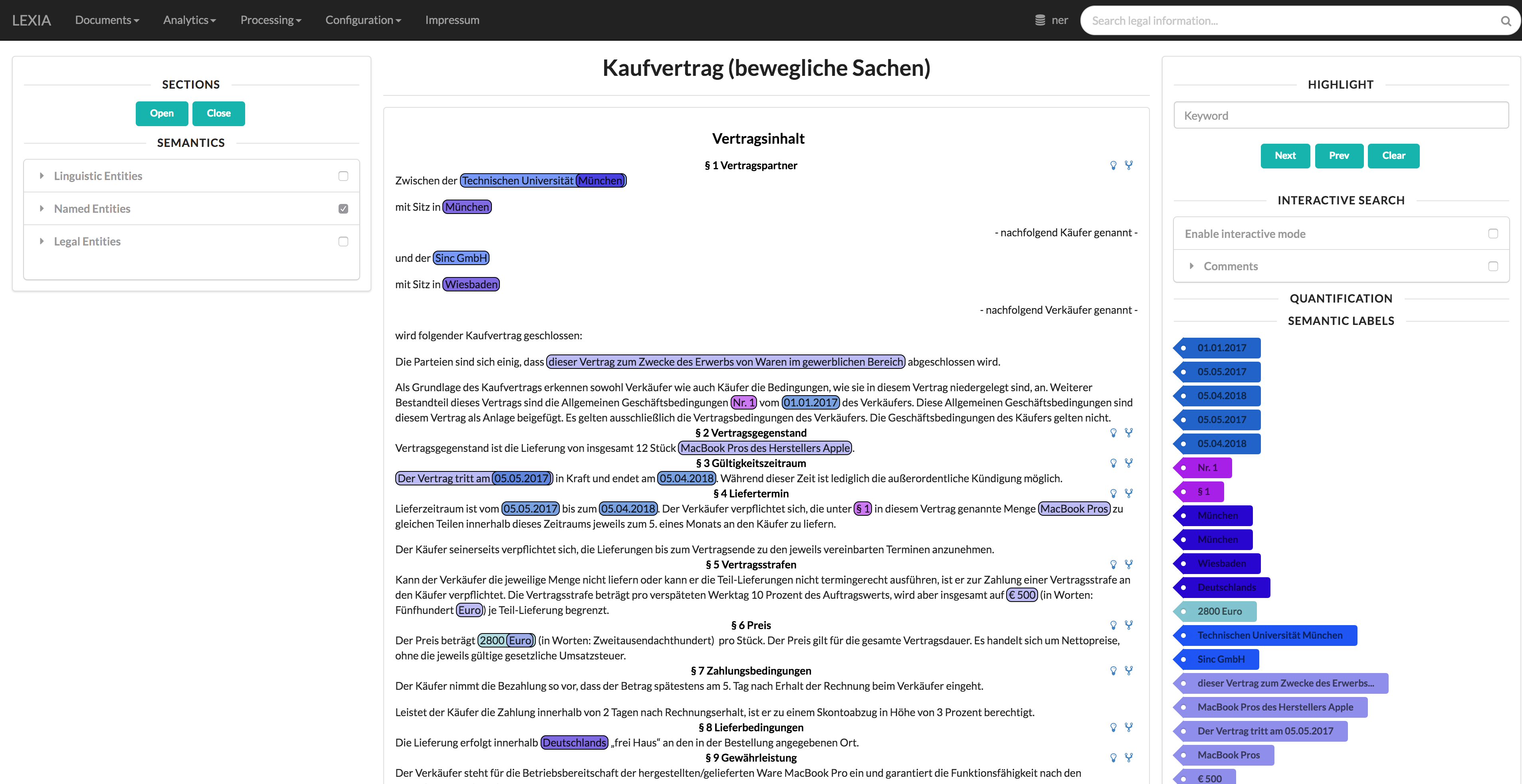
A purchasing agreement with all it´s named entities extracted by our software component is shown in this screenshot.
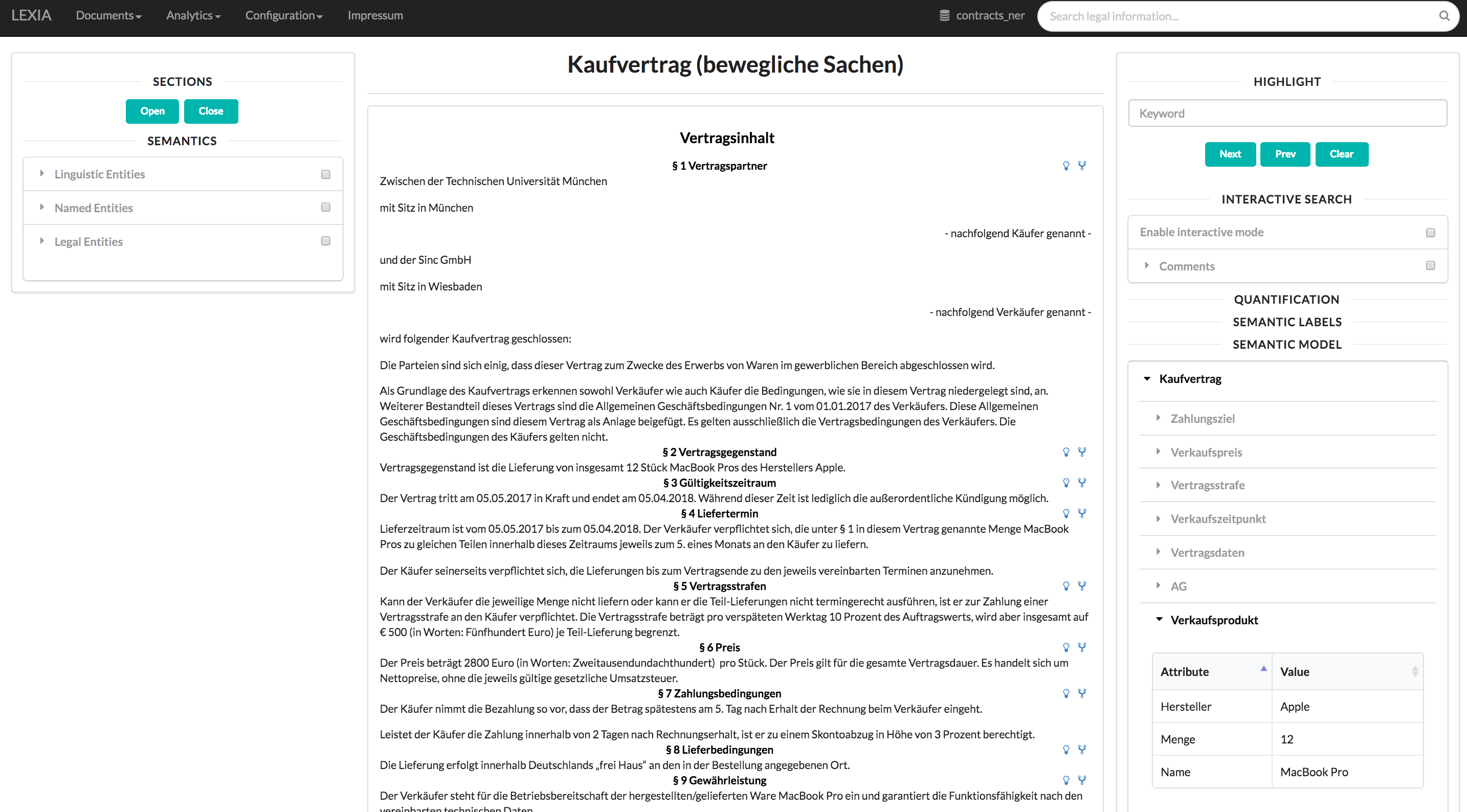
The screenshot above reveals the view including the populated model of a purchasing agreement.
| 2018 | |
|---|---|
| [Gl18a] | Glaser, I.; Waltl, B.; Matthes, F.: Named Entity Recognition, Extraction, and Linking in German Legal Contracts
IRIS: Internationales Rechtsinformatik Symposium, Salzburg, Austria, 2018 (to appear in February 18) |
| 2017 | |
| [Gl17a] | Glaser, I.: Semantic Analysis and Structuring of German Legal Documents using Named Entity Recognition and Disambiguation
Master's Thesis: Technische Universität München, Munich, Germany, 2017. |
We are always looking for research collaborations with industry partners. Therfore, if you are interested in a collaboration in this research project, please do not hesitate contacting Ingo Glaser at ingo.glaser@tum.de.
Hammerton, J. (2003). Named entity recognition with long short-term memory. In Proceedings of the seventh conference on Natural language learning at HLT-NAACL, 03(4), pp. 172–175.
Saravanan, M., Ravindran, B., & Raman, S. (2009). Improving legal information retrieval using an ontological framework. Artificial Intelligence and Law, 17(2), pp. 101–124.
Waltl, B., Landthaler, J., Scepankova, E., Matthes, F., Geiger, T., Stocker, C., & Schneider, C. (2017). Automated extraction of semantic information from german legal documents. In IRIS: Internationales Rechtsinformatik Symposium.