Legal compliance is a key factor for all kinds of enterprises. The reasons for this obligation are diverse. In most cases, these are reputation, security and the avoidance of punishments, fines and losses. Throughout processes in enterprises, legal aspects become increasingly important and especially IT supported processes and applications play a very central role.
However, the assurance of compliance and legal conformity is not trivial. Several aspects contribute to this problem, namely the huge amount of legal texts, changes within legal texts and the lack of their concreteness. Even contracts, which may be concluded regularly, extended or cancelled, are a sort of legal texts and can make binding obligations to services and applications.
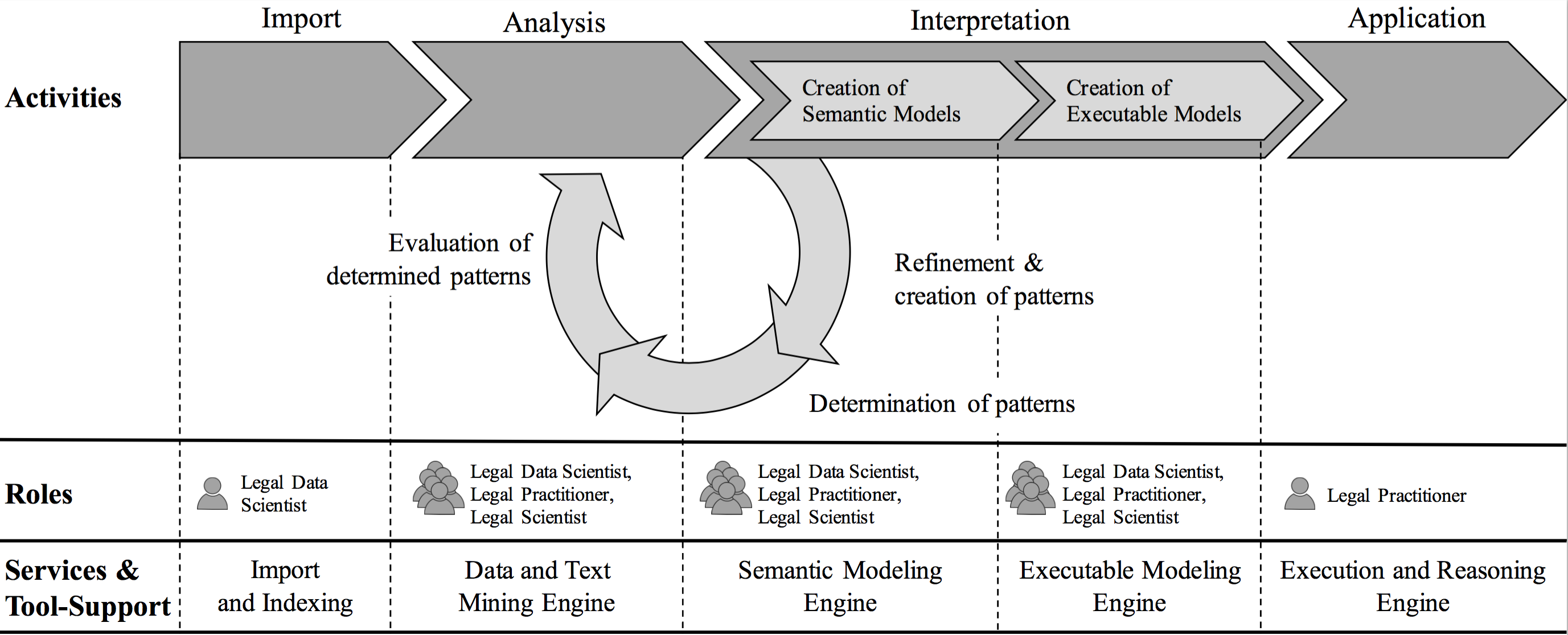
The derivation of requirements from legal texts is a problem, especially to those not familiar with the interpretation of legal texts. Recently adopted legal obligations address a low level of company’s business, namely IT architecture. Consequently, they get more and more in the focus of legal auditing authorities, e.g. Federal Financial Supervisory Authority (Waltl, 2014).
Information systems can assist workers within the interpretation and derivation of requirements from legal texts. In principle, this can achieved using two approaches, namely Information Retrieval (IR) and Artificial Intelligence (AI) (Bench-Capon et al., 2012). Information retrieval on the one hand, focusses on the provision of relevant information that exists in the text (Schweighofer, 2010). Classical information retrieval techniques are full-text search, key word extraction, sorting by various criteria, namely relevance, date, author, etc.
Artificial intelligence on the other hand automatically tries to unveil new structures and information from existing text corpora using logical frameworks or engines (Casanovas, Sartor, Casellas, & Rubino, 2008). Based on the fact, that laws are mostly represented as text, we will use Natural Language Processing (NLP) to extract relevant entities from those existing legal texts (Francesconi, 2010).
The main research questions within this project address:
This research project is funded by German Federal Ministry of Education and Research (BMBF), EIT ICT Labs Germany, furthermore we cooperate with an industry partner, namely DATEV eG.


| 2015 | |
|---|---|
| [Wa15a] | Waltl, B.; Matthes, F.: Comparison of Law Texts: An Analysis of German and Austrian Legislation regarding Linguistic and Structural Metrics, IRIS: Internationales Rechtsinformatik Symposium, Salzburg, Austria, 2015 |
| 2014 | |
| [Wa14b] |
Waltl, B.; Schneider, A. W.; Matthes, F.: |
| [Wa14] | Waltl, B.:
A system theoretical perspective of IT audits in the financial sector |
Bench-Capon, T., Araszkiewicz, M., Ashley, K., Atkinson, K., Bex, F., Borges, F., . . . Wyner, A. (2012). A history of AI and Law in 50 papers: 25 years of the international conference on AI and Law. Artificial Intelligence and Law, 20(3), 215-319.
Casanovas, P., Sartor, G., Casellas, N., & Rubino, R. (Eds.). (2008). Lecture Notes in Computer Science. Computable Models of the Law: Springer Berlin Heidelberg.
Francesconi, E. (Ed.). (2010). Semantic processing of legal texts: Where the language of law meets the law of language. Berlin, New York: Springer.
Schweighofer, E. (2010). Semantic Indexing of Legal Documents. In E. Francesconi (Ed.), Semantic processing of legal texts. Where the language of law meets the law of language (pp. 157–169). Berlin, New York: Springer.