Content Extraction, also die Extraktion des Hauptinhaltes einer Website, durch das Entfernen von Elementen wie Navigation und Header, ist ein wichtiger Schritt im Rahmen des Web Scrapings. Offene Bibliotheken wie trafilatura oder boilerpipe nutzen sogenannte shallow text features um den Inahlt von Blog-Beiträgen oder News-Artikeln zu extrahieren.
Im Rahmen des Projektes KI-gestützte juristische Prüfung von AGB zur Stärkung des Verbraucherschutzes erforscht der sebis Lehrstuhl den Einsatz von KI zur Unterstützung der juristischen Prüfung von AGB. Als wichtiger Schritt in der Verarbeitungspipeline muss hierfür der Text von AGB aus HTML-Seiten extrahiert werden, insbesondere unter Berücksichtigung der Hierarchite und Struktur des Textes, also insbesondere die Zugehörigkeit einzelner Klauseln zu Überschrift und Unterüberschriften. Die existieren Standardbibiliotheken sind hierfür nur sehr eingeschränkt geeignet, da sich der Aufbau von AGB deutlich von anderen Beiträgen unterscheidet, insbesondere durch relativ kurze Texteinheiten und deutlich verschachtelteren Hierarchien.
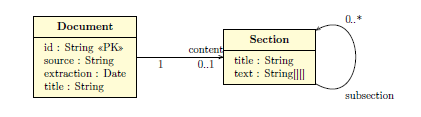
Im Rahmen der ausgeschriebenen Abschlussarbeit soll daher eine Python-Bibliothek entwickelt werden, die den Inhalt von deutschen und englischen AGB unter beibehaltung der Struktur extrahiert und in ein vorgegebenes JSON-Format (siehe Abbildung) umwandelt.
| Name | Type | Size | Last Modification | Last Editor |
|---|---|---|---|---|
| 210426 BA KickOff TSchamel.pdf | 412 KB | 26.04.2021 | ||
| 210815 BA Thesis TSchamel.pdf | 7,49 MB | 10.09.2021 | ||
| 210906 BA Final TSchamel.pdf | 1,19 MB | 10.09.2021 | ||
| BA-Thesis_TobiasSchamel_StructuredExtractionOfTermsAndConditionsFromGermanAndEnglishOnlineShops.pdf | 7,49 MB | 26.08.2021 | ||
| target_format.png | 8 KB | 09.02.2021 |
{kind=link}